
Le web scraping est une méthode efficace pour collecter et analyser des données à partir de n’importe quelle source web. Toutefois, l’utilisation croissante de technologies anti-scraping par les sites web, telles que les CAPTCHA, rend le web scraping plus difficile et plus long. Les CAPTCHA peuvent empêcher les robots et les scripts automatisés d’accéder aux sites web et d’interagir avec eux. Cependant, il existe des bonnes pratiques pour les contourner.
Dans cet article, nous allons explorer les différents types de défis CAPTCHA, les raisons pour lesquelles ils sont utilisés et les techniques que les web scrapers peuvent utiliser pour contourner les CAPTCHA. Que vous soyez un scrapeur web chevronné ou que vous débutiez, il est essentiel de savoir comment contourner les CAPTCHA pour collecter et analyser efficacement les données web.
Qu’est-ce qu’un CAPTCHA ?
Le CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) est un test défi-réponse utilisé pour différencier les utilisateurs humains des programmes informatiques automatisés, également connus sous le nom de « bots ».
Le CAPTCHA est un outil efficace pour empêcher les robots d’accéder aux services web et pour s’assurer que les services web sont accédés par des humains plutôt que par des robots tels que les robots de raclage de sites web ou les robots spammeurs.
Pourquoi les CAPTCHA sont-ils utilisés ?
Les CAPTCHA sont utilisés par de nombreux services web, dont Google, pour protéger leurs sites et leurs ressources contre les activités indésirables ou malveillantes. Voici quelques exemples de CAPTCHA couramment utilisés :
- Empêcher les faux enregistrements: Les CAPTCHA permettent aux propriétaires de sites web de détecter les faux enregistrements et les comptes frauduleux. Ils protègent les pages de connexion contre les attaques automatisées telles que le credential stuffing, dans lequel des acteurs malveillants accèdent à des comptes en utilisant des listes volées de noms d’utilisateur et de mots de passe.
- Prévention du spam : Les CAPTCHA aident les propriétaires de sites web à identifier les robots tels que les robots d’authentification ou les robots spammeurs et à autoriser les contenus générés par les utilisateurs. Les sites web, par exemple, peuvent réduire la quantité de spam généré par les robots en demandant aux utilisateurs d’identifier et de remplir correctement un CAPTCHA. Les CAPTCHA peuvent être utilisés avant qu’un visiteur ne publie un commentaire, n’achète quelque chose ou ne crée un compte, afin d’empêcher les robots d’ajouter des URL malveillantes et de faire du spam.
- Blocage des scrapers de sites web : Les sites web utilisent les CAPTCHA comme méthode anti-scraping pour gérer le trafic des robots d’indexation et éviter que leurs serveurs ne soient surchargés par un grand nombre de requêtes.
- Amélioration de la sécurité des sites web : Les CAPTCHA peuvent être intégrés dans un processus d’authentification multifactorielle (AMF) afin de protéger les services en ligne contre les accès non autorisés et les violations de données. Il est beaucoup plus difficile pour les utilisateurs non autorisés d’accéder à des informations ou à des ressources sensibles.
Pourquoi les CAPTCHA représentent-ils un défi pour le web scraping ?
Les CAPTCHA posent un problème aux pirates du web car ils sont conçus pour empêcher les robots d’accéder aux sites web et d’interagir avec eux. Une page web contenant un test CAPTCHA empêche les robots et les scripts d’accéder au contenu du site et de récupérer des données.
Si un scrapeur web rencontre un défi CAPTCHA, il sera incapable de le résoudre automatiquement et le processus de scraping sera interrompu.
Même si vous avez accédé au site cible, un test continuera à s’exécuter en arrière-plan, surveillant vos activités et vos comportements sur le site. Si vous effectuez des clics rapides ou si le nombre de pages vues est anormalement élevé, le site web que vous scrapez soupçonnera probablement vos activités et vous demandera de passer un test de vérification CAPTCHA.
Certains scrapers de sites web peuvent résoudre certains types de CAPTCHA, tels que les CAPTCHA basés sur des images ou des sons. Cependant, des CAPTCHA plus complexes, tels que les CAPTCHA interactifs ou les reCAPTCHA « No CAPTCHA », peuvent également être difficiles à résoudre pour une personne réelle.
Comment fonctionnent les CAPTCHA ?
Nous avons compilé le fonctionnement des CAPTCHA en 3 étapes :
- Les sites web mettent le visiteur au défi en utilisant des CAPTCHA, généralement sous la forme d’un texte déformé et mal aligné, de puzzles de reconnaissance d’images ou d’un clip audio d’un mot ou d’une série de caractères.
- Le visiteur est censé identifier correctement le mot ou les caractères figurant dans l’image ou le clip audio.
- Si la réponse de l’utilisateur correspond à la bonne réponse, l’accès au site web ou au service lui est accordé.
Vous avez probablement vu des cases à cocher « Je ne suis pas un robot » sur de nombreux sites (figure 2). Il s’agit d’un type de CAPTCHA moins intrusif que les tests CAPTCHA. La case à cocher « Je ne suis pas un robot », également appelée « Pas de CAPTCHA », est une version plus récente de la technologie reCAPTCHA de Google.

Contrairement aux CAPTCHA traditionnels, qui obligent les utilisateurs à saisir des mots ou des caractères déformés, « No CAPTCHA » analyse le comportement de l’utilisateur. Il utilise des algorithmes d’apprentissage automatique pour comprendre comment les utilisateurs déplacent leur souris ou interagissent avec la page.
Si le système détecte un comportement suspect, tel que des clics rapides ou de nombreuses demandes de connexion provenant d’une même adresse IP, l’utilisateur peut être invité à relever un défi CAPTCHA plus traditionnel.
Figure 2 : Technologie reCAPTCHA de Google
Différents types de CAPTCHA
Il existe six types de CAPTCHA différents, chacun étant conçu pour offrir un niveau de protection unique contre les robots et les programmes automatisés. Voici quelques-uns des types de CAPTCHA les plus courants :
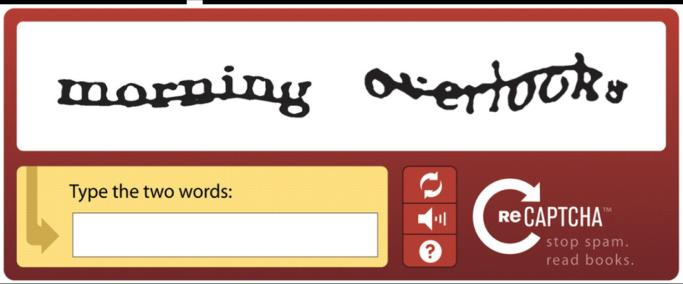
1. CAPTCHA à base d’images
Les CAPTCHA basés sur des images affichent une image déformée d’un mot ou d’une séquence de caractères que l’utilisateur doit reconnaître et saisir dans un champ de texte (figure 3). La déformation de l’image a pour but de rendre plus difficile l’identification des caractères par les programmes automatisés, tout en permettant à une personne réelle de résoudre le problème. Les CAPTCHA à base d’images sont efficaces pour empêcher les robots d’accéder aux sites web, bien qu’ils soient plus difficiles et plus longs à résoudre pour les utilisateurs.
Cependant, certains algorithmes d’apprentissage automatique, tels que les CNN et les SVM, peuvent résoudre avec précision une variété de CAPTCHA basés sur des images. Ces algorithmes fonctionnent en analysant de nombreux ensembles de données d’images CAPTCHA et en formant un modèle pour reconnaître les motifs des caractères dans l’image. En conséquence, de nombreux sites web ont adopté des CAPTCHA plus avancés, tels que les CAPTCHA interactifs et les CAPTCHA « sans CAPTCHA ». Ces CAPTCHA utilisent différents défis pour différencier les personnes réelles des robots.
Figure 3 : Exemple de solution CAPTCHA basée sur une image
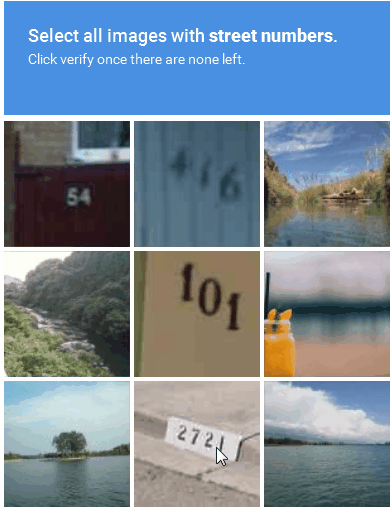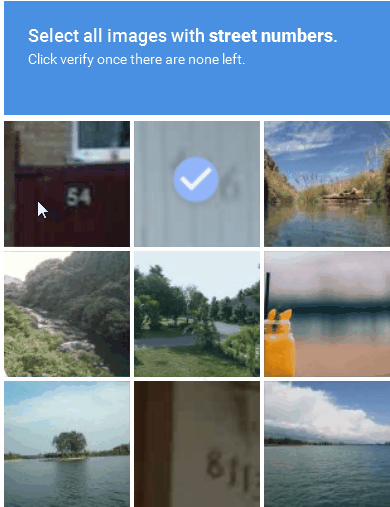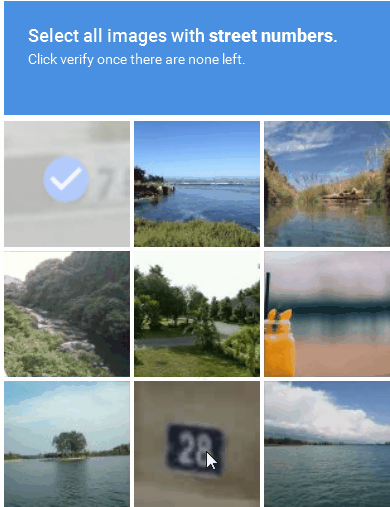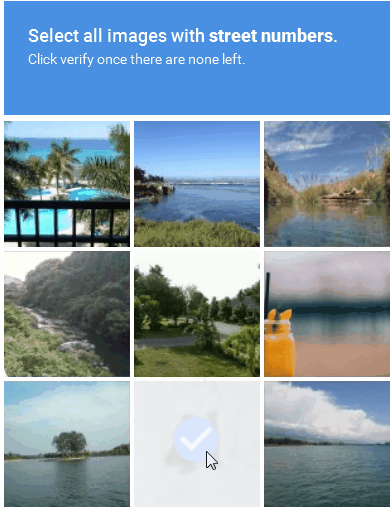
2. CAPTCHA audio
Les CAPTCHA audio présentent un clip audio déformé d’un mot ou d’une série de caractères (figure 4). L’utilisateur doit écouter le clip audio et identifier correctement le mot ou les caractères indiqués dans le clip. Ce type de CAPTCHA est souvent utilisé pour les utilisateurs souffrant de déficiences visuelles.
Figure 4 : Exemple de CAPTCHA audio
3. CAPTCHA textuels
Le CAPTCHA textuel est affiché dans un format étrange et déformé. L’utilisateur doit identifier et saisir correctement un champ de texte pour réussir le test.
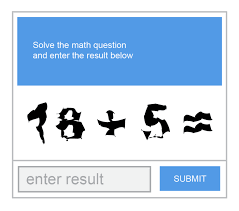
4. CAPTCHA basés sur les mathématiques
Le CAPTCHA basé sur les mathématiques présente à l’utilisateur un problème mathématique simple à résoudre et à saisir dans un champ de texte, tel que « Quel est le résultat de 3 + 2 ?
Figure 5 : Exemple de CAPTCHA basé sur les mathématiques
5. CAPTCHA interactifs
Les CAPTCHA interactifs présentent une série de puzzles ou de jeux que l’utilisateur doit réaliser pour prouver qu’il est un être humain.
6. CAPTCHA à cases à cocher
Les CAPTCHA basés sur des cases à cocher sont un type de reCAPTCHA. reCAPTCHA est un service gratuit développé par Google pour aider les sites web à se protéger contre les activités indésirables et malveillantes.
Le reCAPTCHA à case à cocher demande aux utilisateurs de cocher une case pour confirmer qu’ils ne sont pas des robots. Il peut présenter des défis supplémentaires, tels que la sélection de toutes les images correspondant à des critères spécifiques ou l’exécution d’un simple problème mathématique.
Contourner les CAPTCHA : techniques et astuces pour les web scrapers
Il est essentiel de garder à l’esprit que les défis CAPTCHA lancés sans autorisation sont généralement considérés comme contraires à l’éthique et peuvent constituer une activité illégale. Cependant, plusieurs techniques, y compris les CAPTCHA, ont été développées pour contourner les technologies anti-scraping. Voici quelques techniques courantes pour contourner les défis CAPTCHA :
1. Solutions manuelles :
- Résoudre le CAPTCHA à la main : Le moyen le plus simple de contourner un CAPTCHA est de le résoudre manuellement à l’aide d’un opérateur humain. Cette opération peut être réalisée en interne ou confiée à un service CAPTCHA tiers qui emploie des résolveurs humains. Une solution manuelle peut s’avérer plus rentable que l’externalisation auprès d’un service spécialisé. Cependant, il est important de noter que cela prend du temps et qu’il est difficile de relever des défis CAPTCHA avancés.
- Limiter le nombre de requêtes : L’imitation du comportement humain, comme le défilement et le clic sur des liens, peut donner à votre scraper une apparence plus humaine lorsqu’il parcourt un site web. Vous pouvez limiter le taux de requêtes à un niveau raisonnable, afin que votre scraper ressemble davantage à un humain naviguant sur un site web. Par exemple, les demandes de connexion en rafale peuvent déclencher des limitations du taux d’exploration et d’autres mesures anti-scraping.
2. Solutions techniques :
- Navigateur sans tête : Un navigateur sans tête est un navigateur web ordinaire qui fonctionne sans interface utilisateur graphique (GUI), comme les icônes, les boutons et les onglets. Il existe plusieurs navigateurs sans tête open-source que vous pouvez exploiter, notamment Puppeteer, Selenium et Playwright. En utilisant un navigateur sans tête, vous pouvez automatiser l’inscription pour les pages web qui utilisent la technologie CAPTCHA.
- Proxy : Lorsque vous adressez des requêtes répétées à un serveur cible sans changer d’adresse IP, le site web que vous scrapez détecte une activité suspecte. Il vous présentera alors des tests CAPTCHA pour confirmer que vous êtes un robot.
Les proxys permettent aux utilisateurs de masquer leur adresse IP réelle et empêchent les sites web de révéler leur véritable identité.
Si vous avez l’intention de scraper un site web bien protégé, nous vous recommandons d’utiliser un serveur proxy rotatif plutôt qu’un proxy statique. Un proxy rotatif fait tourner en permanence les adresses IP des clients et attribue une nouvelle adresse IP à chaque demande de connexion (figure 7).
- Améliorer l’empreinte digitale du scraper web : L’empreinte du navigateur est une technique de suivi utilisée par les sites web pour collecter des données sur les appareils de leurs visiteurs. Lorsque vous visitez un site web, par exemple, votre appareil envoie une requête HTTP au site cible afin d’accéder au contenu et de l’afficher. Le site cible peut accéder aux informations que votre navigateur envoie sur vos appareils, telles que votre navigateur web, votre fuseau horaire et votre adresse IP, et les collecter.
Il est important d’améliorer l’empreinte digitale de votre scraper web pour éviter qu’il ne soit détecté et bloqué par les sites web. Pour rendre votre navigateur moins unique, vous pouvez utiliser un agent utilisateur et faire pivoter la chaîne de l’agent utilisateur.
- Utiliser un service de résolution de CAPTCHA : Il existe de nombreux services tiers, payants ou gratuits, qui permettent de résoudre les CAPTCHA. Il est donc essentiel de faire des recherches pour identifier un fournisseur de services réputé. Assurez-vous que le service de résolution de CAPTCHA que vous utilisez est conforme aux conditions d’utilisation du site Web scrapé, car certains sites Web interdisent leur utilisation.


